Maps for the Journey
The steps to Application Modernization for the cloud — Part 2
By Kyle Brown and Yaroslav Dunchych
The biggest problem that most modernization projects face is the simplest. Where do you start? Do you even start? These are real questions because application modernization isn’t something simply or easily done. It takes determination, commitment, time, and most importantly, funding. The Internet is littered with stories of modernization projects that began, seemingly well, and then failed, either quietly with a whimper or sometimes spectacularly, with a bang. In order to find out why this is true, we have to begin with understanding what we are talking about.
In the last section we talked about how you should look at approaching the application modernization journey. Now, what we are going to do is show you the map to that Journey. We’ll take some of the lessons that we’ve described earlier and then show them within the context of an incremental process for application modernization that allows an organization to grow by small successes spread out over time.
An Experience-Based Approach for Modernization
Let’s begin with a map of our modernization journey:
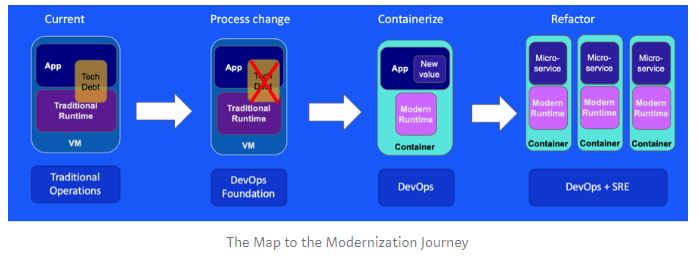
There are four different steps in this map of the journey. The thing you need to realize first is that each step is a potential stopping point for a set of applications. You may choose to move them on to the next step, or for some of them, they will stop at that step until they either reach end of life or are replaced with something else.
Stage 0: Current State
Stage 0 represents the current state of most enterprise applications, especially those written in Java. Your application is probably written as a Java monolith comprised of one or more EAR or WAR files, and is deployed on a traditional Java Application Server runtime such as WebSphere ND or WebLogic. You may have some automation to deploy your application, perhaps written with ANT or using the vendor’s deployment scripts, but the process for deployment, upgrade and management is at best, semi-automated.
The key realization here is that there will be some applications that will never leave their current state. There are several reasons why this would be true. #1 The application may have a limited lifetime. If you are going to retire an application, then there is no need to modernize it. #2 The application may be replaceable by SaaS. If the application (at least in its current form) can be entirely replaced by a SaaS application, then in many cases that is the simplest and easiest route. #3 The application may be one that is supported by a vendor or third party ISV that is resistant or even hostile to changing their implementation, automation or management. If that is true, then that should be a reason to start looking for other alternatives (SaaS or other…)
We would hope that the number of applications that fall into this category are small, but realistically, the number can be large. For companies that consider themselves to be “technology companies” this figure may be in the low double digits, perhaps 20–30%. However, for companies that explicitly do not consider IT to be part of their business competency (as often evidenced by large outsourcing contracts and wide reliance on packaged software) the number can be quite large — we have seen up to 80% in some companies that are part of mature industries. When costs savings becomes the driving force in IT and completely subsumes innovation, then this end state is nearly inevitable. When that is true, that may be an indication that this particular company, or perhaps the entire industry, is ripe for disruption.
As a side note, there is a single, thin thread leading to a way out — in some cases it may be possible to reduce overall TCO of the solution by doing a VM lift and shift to the public cloud. However, this is, at best, a tactical decision and not a strategic decision. If it makes sense to balance OpEx for CapEx for your particular organization, this can be valuable. For instance, in one client I am familiar with, they were facing a multimillion-dollar hardware upgrade charge from their datacenter vendor just for keeping their applications where they were. For them, avoiding this charge essentially made the business case for them to perform this move as the first step of a longer cloud modernization journey. But it was that longer journey that was critical to their strategic direction.
Stage 1: Process change: Apply Automation and basic DevOps principles
Stage 1 is where you still have the same application, but you have begun to pay down technical debt in a couple of important ways. First of all, you are on a supported version of your dependencies, such as operating system and application server runtimes, but more importantly, you have made the investment in your people to begin putting modern DevOps principles in place.
We have to emphasize this point — in most cases, it’s not your application that is going to be the hard part of moving to the cloud — it’s your own processes and organizational structures. Over and over in dozens of application modernization and cloud-enablement projects we’ve seen that these “people” issues are much, much harder to solve than the technical issues. Nonetheless, there are technologies and approaches that can help break companies out of their existing models and begin to pave the way to the cloud. In particular, the two most important that we see are DevOps pipelines and the principles surrounding them (e.g. CI/CD and Automated Testing) and the principle of Infrastructure as Code and automation technologies like Ansible, Chef and Puppet.
Essentially, the first thing a team needs to do to become successful at developing for the cloud is to become successful at modern software development techniques and strategies. A primary goal of many cloud adoption journeys is to reduce the cycle time of releases. However, cloud technology is only an enabler of that — not a magic bullet to make your developers faster at doing things the same way. Reducing cycle time involves many related issues; you have to first reduce the scope of each release — this is the idea behind many Agile project planning techniques like Kanban and User Stories. Second, you have to make each release self-contained; this requires you to adopt techniques like automated testing. Finally, you have to remove manual process steps not only in testing, but in execution of tests and integration and release of code; that’s the idea behind Continuous Integration and Continuous Delivery. Cloud technologies only begin to really become helpful after you’ve started to follow each of these techniques.
In existing environments, the technique of infrastructure as code, where development and test environments are created, destroyed and deployed to entirely through code is important to becoming successful with adopting CI/CD. Now, that last point is worth discussing in more depth. This is the first time we’ve discussed writing net new code, even if it is infrastructure automation code in Ansible, or another tool. This is a great time to develop some additional skills in your team, particularly around the idea of Test Driven Development or Behavior Driven Development. If you can first write the tests that check that what your infrastructures look like meets what you think they should look and respond like, then you will have an easier time ensuring that your environments are not only correct, but always identical. Tools like Molecule can help with testing Ansible code in this way, and this combination will work regardless if you are working on an on-prem environment like VMWare, Red Hat Enterprise Linux, or OpenShift — and will continue to work with most cloud providers when you are ready.
One important additional thing to note is that we’re not changing the application code yet, or at least not in any significant way. We’re not refactoring. If you can start paying back technical debt by updating the versions of your operating systems or middleware to a supported level, then that is a great thing, but you have to realize that some applications may never leave this state. For applications that aren’t often modified, that do not have driving business needs to reduce their development or operations costs, and that have no business drivers for new features, this state is likely permanent.
What we have observed is that the type of change that application modernization causes to an organization requires proactive organizational transformations in order to ensure the change will last. It is essential for success that people welcome the change and choose to engage in new processes and use the new technologies in order to achieve their desired outcomes. The organization’s leadership must inspire autonomy and ownership through stating a clear vision, modeling desired behaviors, and giving people permission to change. Continued growth requires that the vision be kept up to date so that at each step, everyone can see where they are going and understand why they are going there. In the IBM Garage, we have successfully used IBM Enterprise Design Thinking techniques to obtain that kind of alignment around a shared vision, and to help teach executives how to maintain that shared vision over time.
Another important type of “people” issues is related to current organizational capabilities and whether or not they are ready to support application modernization journey. Many IT organizations today are only focused on ‘keeping the lights on’ for a stable application portfolio. Existing organizational capabilities have matured over years, and you may not think about taking a fresh look at your skills and capabilities if your organization is directed to start application modernization efforts.
One way we have done this is to practice a classical “red team” approach in starting application modernization efforts in order to discover implicit gaps in organizations capabilities. In this process, we double check implicit assumptions from the outside and conduct individual interviews in order to overcome groupthink. This is a collaborative effort to provide actionable recommendations in order to refresh processes and practices in the client organization that are essential for modernization success.
Stage 2: Containerization of existing applications
Containers themselves bring some significant benefits; faster startup, smaller runtime footprint, denser packing in the same amount of hardware. However, the key thing to realize is that if you containerize your applications, there are additional benefits you pick up — not only do you gain the benefits of containers, but you can also gain the benefits of a common platform for containers.
Most people in the cloud industry are familiar with, or at least heard of, the analogy that compares traditional servers to Pets and cloud servers (it has been applied to everything from AWS VM’s to Kube Containers to Serverless runtimes) to Cattle. The basic idea is that if you have to care for and maintain a server — if it feels indispensable — it is a pet. A server or process that can be started and restarted at will, especially in multiple copies, is just a nameless member of the herd.
What Containers and Kubernetes does is to not just reinforce that notion, but to make it central to the way you operate your systems. By making each container immutable (e.g. making it hard if not impossible to modify the OS or other software while the container is running) it forces you to begin treating all of the components of your systems as cattle. This is important in that it fundamentally changes the way you do operations — you never patch the components of your applications — you simply replace them. It also may change the way you write your applications — if an application is not designed for scaling, or if would suffer an outage if a particular application server or other component is stopped and replaced, then you will need to first rewrite your application to allow for these conditions before you containerize them.
However, this is only part of the value of what you get when you containerize. While immutability definitely has its benefits in terms of predictability of deployments and reproducibility of errors, another reason that is just as important is that replacement as an end-state of a DevOps process is vastly simpler than trying to modify a running server or process. Strategies like Blue-Green Deployment and A/B deployment are easier when you can recreate an entire stack at will and create as many instances of a component as you need. OpenShift, for instance, supports all of these as a standard part of the routing and deployment process (https://docs.openshift.com/container-platform/3.3/dev_guide/deployments/advanced_deployment_strategies.html)
But a container platform provides even more benefits. Fundamentally, workload containerization provides a solution for one the major challenges with any application modernization efforts, the ‘middleware hairball’ problem. This problem originates from a highly interdependent nature of applications and middleware instances in existing deployment landscapes, exacerbated by shared nature of middleware instances. This is illustrated in the left part of the diagram below, where several applications are shown as sharing multiple instances of various middleware (MW) types (such as Messaging software like IBM MQ, API gateways like IBM API-C, etc.)

A corollary to the cattle approach for container deployment is that each single-function container is the opposite of the traditional shared monolithic middleware instance (a pet). One approach to untangling the ‘middleware hairball’ is un-sharing and decoupling middleware functions used by an application into a separate single function containers that logically become part of the application itself. This decoupling is illustrated in the upper right part of the diagram.
There is also an operational aspect of the ‘middleware hairball’ problem as each middleware type in traditional deployment has a separate operational tower because of different ways that common operational tasks are addressed by different middleware stacks. The container platform changes this and provides unified container operations. Having a common logging strategy, a common monitoring strategy, a common identity and access management (IAM) strategy and a common secrets management approach across all applications and middleware means that you can replace your current DevOps silos with a more uniform set of tools and techniques that apply to many different workloads.
If this is your next step, you need to determine where you can start if you want to containerize your existing application. You have to determine what technical debt you need to pay back, which applications should be containerized in which order, and what technical decisions are crucial, and which are nice-to-have. Luckily, IBM can help you with that. The Transformation Advisor is a tool that comes with the IBM Cloud Pak for applications (it’s also free to use if your destination for transformation is the IBM Cloud in any form) to help you make the right technical and prioritization decisions. It’s the first concrete step to take toward containerization.
Let’s take a closer look at containerization. The basic premise is to keep the application unchanged since the biggest change will be the operations modernization required to adopt a container orchestration platform. This requires you to master Kubernetes from an operational perspective, which is not a trivial task. Once you decide to take this route, there are are two commonly used patterns for application containerization.
Repackage: Lift & shift to containers
The repackaging containerization approach is about repackaging existing application into a container with as little change as possible (preferably zero). Achieving zero application change also means preserving existing application runtime dependencies, such as a traditional application server runtime, which is required to support the older platform functionality used by the application.
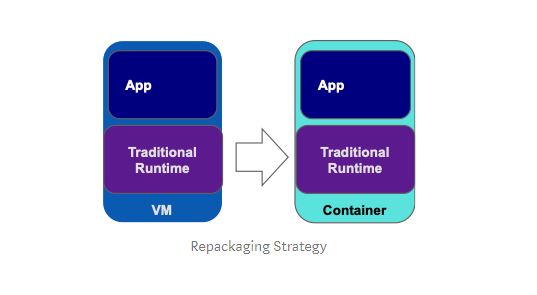
For example, a WebSphere ND application running in a traditional WebSphere environment can be moved to a container “as is” using a container image that already contains traditional WebSphere. The ease of movement to containers using this approach is dramatically simplified when you use pre-built certified container images with a traditional WebSphere runtime (as are provided with the IBM Cloud Pak for Applications). However, while fast, this isn’t always the happy ending to your journey for modernizing Java EE applications. Let’s take a closer look to understand why.
Traditional Java EE runtimes like WebSphere have been designed as large monolithic application servers with full set of features always available, and typically have a long startup time measured in minutes and large runtime footprint. This creates certain limitations for using such containers in container orchestration platform such as Kubernetes where it is expected for containers to be routinely restarted and moved around. The high resource requirements will put constraints on node size and placement, and other aspects of planning your Kubernetes environment.
An even more critical requirement for sustainable containerization is to switch from the ‘pet’ to ‘cattle’ modes of operating applications in a container. This requires a substantial operational modernization effort to convert from high touch ‘pet’ type application administration using traditional administration console UI or ad hoc set of scripts to the use of fully automated CI/CD container deployment pipelines for ‘cattle’ approach. Our experience has shown that while it is possible to build automated pipelines to operate traditional Java EE runtime in container following ‘cattle’ model, it is not entirely seamless and comes with its own set of limitations.
So where does this leave us with repackaging containerization approach? Given the above considerations, for apps based on full-featured traditional Java EE runtimes this kind of “lift and shift” containerization should be considered primarily as a “plan B” that is only applicable when application change is not possible or desirable. That said, for Java and non-Java applications that do not have explicit dependencies on Java EE server runtimes, for example Java Spring Boot apps, the repackaging approach is more straightforward and is often the “plan A” option for containerization.
You can find a complete end-to-end scenario of the repackaging containerization approach for a traditional WebSphere ND application moved to Open Shift in the IBM Garage Architecture Center:
https://www.ibm.com/cloud/garage/architectures/application-modernization/op-modernization
A recorded walkthrough demo video of the process is also available here:
https://mediacenter.ibm.com/media/Cloud+Pak+for+Applications+-+WebSphere+Operational+Modernization/1_g46hm9ys
Replatform: Augment for Containers
This approach to containerization does not change the general intent of minimizing the application change required for containerization, but it allows you to fully realize the benefits of containerization and container orchestration platform by optimizing application runtime dependencies. In order to accomplish this, the traditional runtime used by an application, such as IBM WebSphere, is replaced with next generation modern container-native runtime such as Open Liberty, which is highly optimized for use in container environments with small footprint, fast startup and DevOps friendly infrastructure as a code configuration.
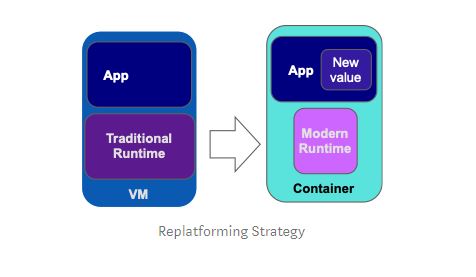
Replatforming an application to a container using a modern runtime makes it much easier to develop and demonstrate new value associated with application modernization. New value can come in multiple forms:
· functional augmentation based on ease of consumption of innovative cloud services facilitated by new application APIs provided by modern runtimes
· operational augmentation based on pre-built integration with common container services such as logs aggregation and analytics, monitoring and events, etc. provided by modern runtime
· development productivity augmentation with the capability to dynamically bring up and tear down container based testing environments quickly on demand
However, replatforming your applications from traditional Java EE runtimes to modern runtime such as Liberty, requires prioritizing your technical debt into those parts that are critical for the move, and those that are merely “nice to have”. The IBM Transformation Advisor is a tool that comes with the IBM Cloud Pak for Applications (it’s also free to use if your destination for transformation is the IBM Cloud in any form) to help you make the right technical and prioritization decisions.
You can find a complete end-to-end scenario of this containerization approach for a traditional WebSphere ND application to Open Shift in the IBM Garage Architecture Center here:
https://www.ibm.com/cloud/garage/architectures/application-modernization/runtime-modernization
likewise, a recorded walkthrough video is available here:
https://mediacenter.ibm.com/media/Cloud+Pak+for+Applications+-+WebSphere+Runtime+Modernization/1_x1xntvmz
Refactoring to cloud native
It is only after you’ve mastered the Agile and DevOps principles and practices we discussed earlier, and also after you’ve understood and mastered Containers and Kubernetes that we would recommend that you begin a major cloud-native refactoring effort. Unfortunately, this is the exact opposite of what we see many teams do in practice.
Far too often we have seen a team decide to take on all of these things at once. However, what quickly happens is that the complex interactions of all these new practices and technologies will overwhelm teams and cause them to fail. The result is that all of the required pieces; Agile, DevOps, Containers and Refactoring, all get tarred with the same brush. So how do you avoid this outcome? We’ve already seen the first part — adopt new techniques and technologies slowly. But something we’ve not talked about is how important these techniques are to the success of a refactoring effort.
Let’s start with one of the fundamental aspects of any effort to refactor a monolithic application to become cloud-native — it’s called the Strangler Pattern, and it was first elucidated by Martin Fowler back in 2004, see (https://martinfowler.com/bliki/StranglerFigApplication.html). The basic idea is simple — you replace the parts of your existing monolithic application one piece at a time while leaving the existing monolith in place to handle the so-far unchanged functions of your system. The idea as it has developed for cloud-native modernization is that you extract microservices one or two at a time from the monolith and those become the “strangler vine” that replaces the original monolith.
But there’s a fundamental step that you need to make sure you have in place before you begin a microservices that goes back to an even earlier work by Fowler — his book Refactoring: Improving the Design of Existing Code (https://martinfowler.com/books/refactoring.html). One of the things that Fowler makes very clear in that book (and which was already clear in the earlier works on refactoring by Ralph Johnson and others) was that Refactoring as a process only works when you have an existing and comprehensive suite of tests to run against both the original and new code. You see, the idea is that a refactoring is meant to be a “behavior-preserving” transformation — the only way you can be sure that the behavior of the original system is being preserved is by comparing the results of running tests before and after the transformation.
As a result, Test Automation (as we described earlier) becomes absolutely essential to any refactoring effort. What’s more, what we have seen in practice is that the extracted microservices rarely only duplicate the existing functionality of the original system. Let’s face it — the only reason why the business would allow a team to begin a refactoring effort was to make it easier to implement new features that are on the backlog. So instead, those extracted microservices often end up implementing both existing functionality and new functionality as well.
This convergence of the two desires — to extract the existing features of the code and add new functionality into these new microservices means that you are in effect, trying to hit a moving target. The only technique that we have found that helps you to hit that moving target is if you are able to define precisely what definition of new and old behavior should look like before you implement it, and be able to test to that new definition. That is what Test Driven Development provides you. So when you begin the refactoring process, Test Driven Development becomes absolutely critical.
Another thing to think about is how far you take the refactoring to microservices. No one will dispute that Microservices are a wonderful technique for building loosely coupled applications. But the microservices technique has ramifications. For instance, if you do it right, each Microservice is independent in scaling, deployment, data control and team ownership. But the question is, is all of that needed for every part of your application?
Start by asking yourself a few questions first
• How large is the application? If the application is already small, then breaking it up even further into microservices may not accelerate your testing and make deployment more complex.
• Does it all change at the same rate? Where microservices shine are when different parts of the application change at different rates — decoupling those parts from each other allows you to let the fast-moving parts change quickly, while retaining stability in the other parts and requiring less testing overall. If it all changes at the same rate you don’t encounter the same types of problems.
• Are you reintroducing coupling by building complex microservice networks? By now most of you have seen the “big blue ball” picture of the microservices architecture in use at Netflix (https://www.zdnet.com/article/to-be-a-microservice-how-smaller-parts-of-bigger-applications-could-remake-it/). The thing is, that should concern you as much as excites you. If you recreate the same tightly coupled architecture in your microservices as you did in your monolith you’ve really not gained anything.
It all comes down to why you are trying to refactor an application into cloud-native microservices. Doing it to sharpen your resume is not a good reason. Instead, the things to keep in mind in the new model are: Can your application be maintained, can you sustain rapid, incremental releases, and do your operational approaches allow you to identify problems quickly and return to service immediately? If breaking a monolith into Microservices helps you achieve these goals, then that is a tool you can use, otherwise don’t pursue them.
We have often seen that these strangulation exercises tend to fade out over time with a whimper rather than a bang. After the first few extracted microservices, it often begins to become harder and harder to extract new microservices from the monolith that help you with your business goals. What I’m going to suggest (and this idea originally came from Pini Reznick at Container Solutions, who has a book coming out on this subject) is that at some point, cutting your losses and simply leaving the last shriveled remnants of the monolith as a smaller mini-monolith may be your best option.
One last thing to consider — refactoring to microservices increases complexity on operations as the number of running containers will dramatically increase as more and more microservices are deployed. The complexity of running microservices in containers is exacerbated by the near infinite level of diversity of the polyglot open source applications workloads in those containers. Container orchestration platforms provide common operational services such as consolidated logging, monitoring framework, alerts management, requests tracing, operators framework etc. However, application workloads still need to be able to exploit these platform services to empower application teams to understand and optimize the runtime characteristics of their application workloads. This means that operational features of the microservices applications have to be treated by applications squads like any other application features and microservices operations effectively become part of engineering. Embracing this “shift to the left” trend in microservices operations as part of building an SRE (site reliability engineering) capability in the organization is essential to successful microservices adoption.
What’s next?
What we’ve discussed in this section is are some of the technical issues involved in a modernization journey and the ramifications of those decisions. However, as we discussed earlier, these aren’t the hardest problems you will face. The hardest problems are in creating alignment between teams and changing your organization and process to meet the needs of the new technologies and ways of working. That’s the subject of the next section as we investigate ways of meeting teams where they are and getting everyone moving in the same direction.